History & Evolution of CAPTCHA
Innovation is an ongoing process. We started from a text-based CAPTCHA and reached a simple checkbox you have to tick, making adaptations after each failure.


You're visiting a website to purchase plane tickets for your next flight. Before you can hit submit, you need to tick a box asking if you're a robot?
At first look, it seems like irony at its best. Why would I need to confirm if I'm a human or not and that too, to a computer?
And even if I do tick that box, how does it confirm that I'm a human? Can't a robot tick the same box?

It's like the jury asking a murderer if he has killed someone or not. "Of course I haven't murdered anyone" - would be the murderer's response.
So, what's the need for that question? Why do CAPTCHAs exist? And how do they test whether the user is an actual person based on simple requests?
We'll cover all of that in the article and most importantly we'll analyze how CAPTCHA has evolved over time, its different versions, and more. So, stay tuned!
Table of Contents:
What is CAPTCHA?
CAPTCHA stands for Completely Automated Public Turing Test to Tell Computers and Humans Apart.
Well, that's quite a complicated acronym. Worry not, we'll simplify it for you.
What's a Turing Test?
The legendary British mathematician and computer scientist Alan Turing was having arguments with his colleagues and critics over if a machine (digital computers) could ever have a human-level intelligence?
To prove his point Turing proposed a game. In this game, an interrogator would ask questions to a human and a computer through a text-only chat. If the interrogator doesn't find any difference between both their responses and the computer can successfully project itself as a real human then it passes the test. Turing called it 'the imitation game'.
Who knew that decades later the same test principle would be used to set up CAPTCHA. But this time around to tell computers and humans apart.
In 2000, a 22-year-old youngster named Luis von Ahn along with his professor Manuel Blum developed CAPTCHA in order to prevent automated programs from attacking different networks and websites.
Why do we need CAPTCHAs?
You must have heard the term- Bot. Bots are software applications that can do certain tasks on their own basis the script given to them. They often imitate or replace a human user's behaviour and carry out the tasks way faster.
There are helpful bots such as search engine bots that scan the webpages to index content for users or chatbots that simulate human conversation.
But then there are malicious bots that can annoy users by spreading spam content, taking over certain accounts, or even bringing down huge websites carrying out DDoS attacks.
Here are some other malicious activities that can be performed by malicious bots-
- Credential Stuffing
- Content Scraping
- DoS or DDoS attacks
- Email address harvesting
- Spam Content
- Brute Force password cracking
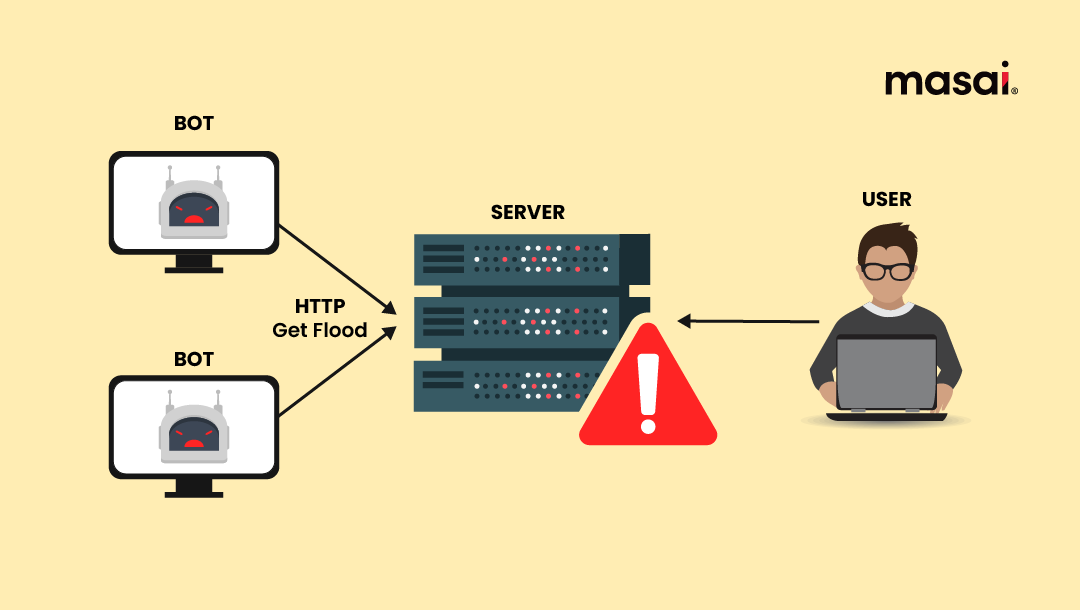
If left free, these bots can run amok and create all kinds of problems. Problems such as-
- Damaging the integrity of online polls
- Breaking into online accounts using brute-force attacks
- Causing ticket touts by bulk buying tickets and reselling them
In one such case, a big supermarket brand Target suffered a data breach that affected 70 million people back in 2013. At that time, Target's vendor portal didn't have a CAPTCHA in place. The havoc seemed to have been caused by a phishing email that went after their customer base.
And that's why we need CAPTCHA to stop people from playing the system, to stop actions that can affect millions of users on the internet and possibly pull off huge frauds.
How does CAPTCHA work?
In most cases, CAPTCHAs depend on visual tests, taking advantage of the fact that automated bots lack the sophistication of human beings when processing visual data.
So, it all started with some weird warped text that we had to decipher in order to sign in to a particular website or even add a comment.
In a way, it wasn't fully automated as we had to type in the text but let's just call it 'Completely Automated'. Yeah, why not?
Types of CAPTCHAs
CAPTCHAs generally fall into three main categories-
- Text-based CAPTCHAs
- CAPTCHA Image
- Audio CAPTCHA
Let’s get to know all of them one by one-
Text-based CAPTCHAs
These are the oldest form of CAPTCHAs that use known words or phrases, random warped texts, combinations of digits and letters, etc.
These characters are presented in an abnormal way, something that is hard to be interpreted by automated programs.
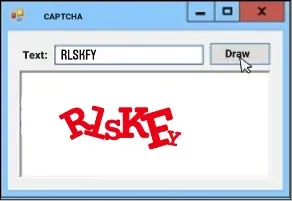
It can include distorted characters, rotation, indifferent scaling, etc.
Some CAPTCHAs may also involve overlapping characters with graphic elements such as color, background noise, lines, etc.
Image-based CAPTCHA
All of you would have come across CAPTCHAS which asks you to tick the images that contain traffic signals or cars or other objects.
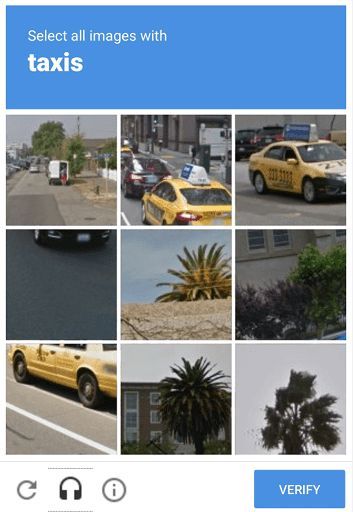
These are image-based CAPTCHAs that are easier for humans and more difficult for bots to interpret; as they require both image recognition and semantics classification.
Audio CAPTCHA
Text-based and Image-based CAPTCHAs couldn't cater to visually impaired users. And that's why Audio CAPTCHAs were developed.
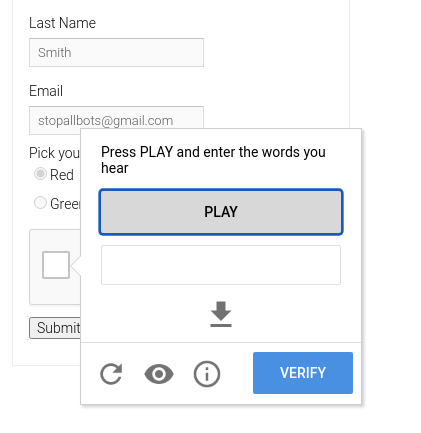
They are used in combination with an image or text-based CAPTCHAs and present an audio recording of a series of letters or numbers.
These recordings generally contain background noise, thus making it difficult for bots.
Birth of reCAPTCHA
With millions of people completing these tests every hour, it was working out fine.
But as innovation knows no bounds, Luis von Ahn sensed another opportunity.
What if we could save all those hours that are wasted computing random warped texts for different users and use old unreadable book scripts instead?
In an interview with The Walrus, Luis said that he’d created a system that “was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles.”
And true that! The overall computing of 200 million words per day would add up to 500,000 hours of wasted human brain potential.
That’s when he came up with the idea of using real, unscannable texts from old books as verification texts.
The Optical character recognition (OCR) couldn't read about 20% of all scanned words at the time.
Luis's new idea would put all that wasted human effort to good use as now users would be unknowingly helping the OCR decode those unreadable words from old books and feeding them into the system.

This new version of CAPTCHA came to be known as ReCAPTCHA. And the first ever book to be digitized using this method was the New York Times archive. (Started way back in 1851 with 13 million articles to date)
How does reCAPTCHA work?
It works along the lines of Crowd-sourcing. First, a book is digitally scanned by the admin of the reCAPTCHA program. The program picks two words from which one word is already readable by the OCR.
On the other hand, a user has to guess both these words in the reCAPTCHA box. If they guess the first (readable) word correctly, the program assumes their second guess to be correct as well.

The second word is then presented to other users. The program compares all responses and finally, it has enough evidence to verify the word with a high level of conviction.
And in this way, the program serves a two-fold purpose by making us do the hard work without a salary(well, it wasn't that hard, to be honest)
- It verified if the user is a human or not
- It verified the word that couldn't be read by the OCR and digitized it for human knowledge.
Google saw the bigger picture and purchased reCAPTCHA in 2009 for use in Google Books.
They used reCAPTCHA to get humans to identify words, or characters that their image processing algorithms weren't able to identify, and quite wickedly used us to ease this process.
Google Books was an ambitious project to digitize every book in the world and create a huge digital library for all to access.
According to Wikipedia, Google had scanned over 40 million books by October 2019. The project however hasn't concurred as planned due to a series of legal battles between authors, publishers & Google over Copyright issues. (Learn more about it here)
Challenges with reCAPTCHA
As the system gets safer, the thieves get smarter. And that's what fuels the perennial evolution cycle.
A 2014 study by Google suggested that modern Artificial Intelligence technology could solve even the most distorted of texts with a 99.8% accuracy, and numbers in images with a 90% accuracy.
Processing visual data wasn't to be a dependable testing option anymore. It was needed to find a fresh filtering approach.
NoCAPTCHA reCAPTCHA
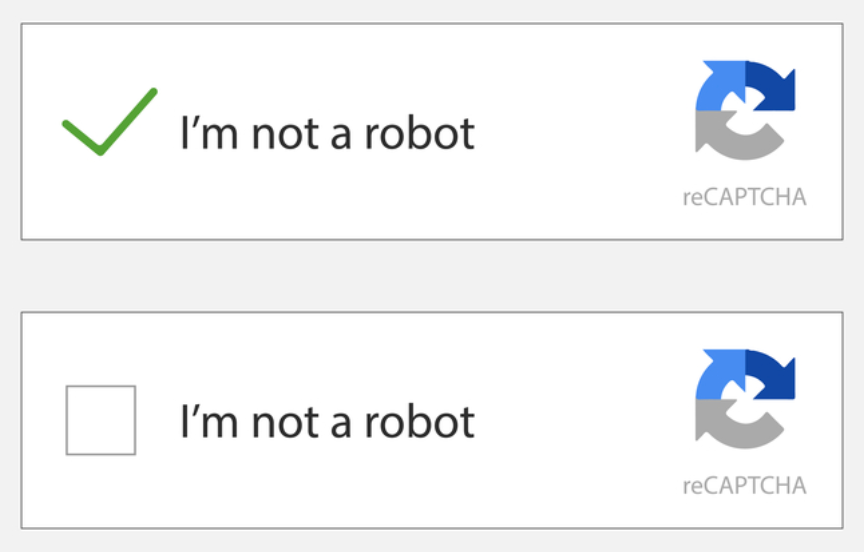
And then came the revolutionary API that we use today - NoCAPTCHA reCAPTCHA.
Yeah, the same simple checkbox that we talked about at the beginning of this article. All it requires is just a tick, and then you can go about your usual business.
How does NoCAPTCHA reCAPTCHA work?
It's actually way more sophisticated than it looks. It works on an Advanced Risk Analysis API that keeps running in the background. It tracks a user's entire engagement with the CAPTCHA - if the cursor has moved before reaching the check box, during the verification, and after you've ticked the box. The user's whole interaction determines if they're human or not.
Why does it work?
The central idea behind this is that automated malicious bots have a pre-written script, a program to execute the function. If a bot tries to sneak into the check box, it'll have a code to execute the tick function. It wouldn't hover around the screen as we humans do through the cursor.
Thus, the NoCAPTCHA reCAPTCHA program can detect if it was a script or a manual function.
However, even this method is not completely secure as it is entirely possible to create a program that can perform mouse clicks on your computer and tick the check box.
And that's why Google might even take into account cues that every user unwittingly provides such as IP addresses and cookies, that can prove you're just a friendly human.
To be honest, we still don't know all the methods used by Google to detect boots. (Let's leave that to Google, shall we?)
What if it's still not enough?
Even after this sophisticated level of security, uncertainty can persist. Keeping that in mind, Google introduced an extra validation step to tell humans and bots apart- image identification.
When the engine is not too sure, it asks the user to verify with the old style CAPTCHA (text and numbers) on desktop and image clue style CAPTCHA on mobile phones.
There's also a form expiration timer running in the background to prevent bots from solving CAPTCHAs.
Next CAPTCHA innovations
Innovation is an ongoing process. We started from a text-based CAPTCHA and reached a simple checkbox you have to tick, making adaptations after each failure.
In fact, every CAPTCHA test failure leads to an advancement in artificial intelligence. How?
Because for a test to fail, someone has to find new methods to tell a computer how to solve the test.
And that gives us the fuel and fire to further come up with new CAPTCHA tests.
One such innovation is - The Honeypot method.
How does the Honeypot technique work?
It actually uses deception to lure the bots into revealing themselves. If we roll out a form, we know that automated programs will fill out all the fields in the form. And so would a human being but only the fields they can see.
What if we created some fields that are invisible to users but are there in the form?
The spam bots would surely fill those fields too and give themselves up.
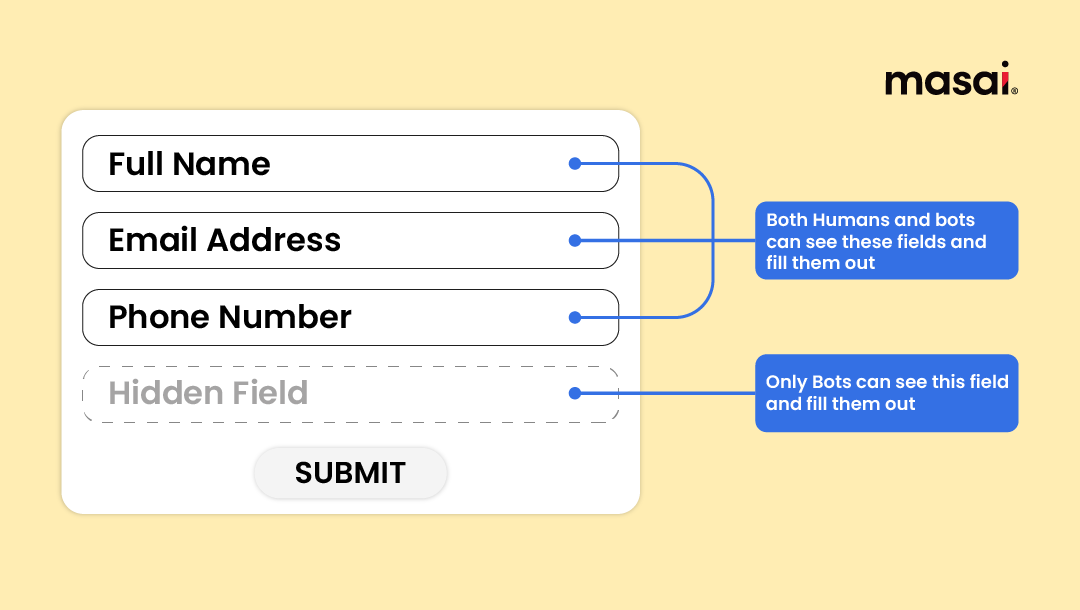
This Honeypot technique acts as a double-edged sword - easing out the verification process for human users and effectively catching those pesky spam bots.
What’s the future of Cybersecurity?
However, as we discussed earlier, anything engineered can be reverse engineered if one has the motivation to do so.
CAPTCHAs were developed to stop harmful bots from propagating spam messages. But the bots didn't stop there. Today bots are assaulting servers, stealing data, and conducting frauds, among other things.
With motivated opponents like CAPTCHA farms, and smarter AI, the question stands - Are CAPTCHAs really effective, or are they just speed-bumps to be bypassed by attackers?
Another challenge with CAPTCHA security is customer aggravation. Nobody wants to fill a form or guess random images for simple actions like login, or registration to offer security to the website.
It's in no way a viable, long-term solution. And we also don't need just bigger speed bumps. More complex CAPTCHAs have been developed in the past and as we've seen, AI and Machine learning technologies have readily bypassed them as well.
Thinking needs to be in a different direction altogether. Online businesses must invest in new technology to detect bots and at the same time, maintain a positive user experience.
Maybe it's already underway? Who knows we might get to see that in the next 5 years?
That's the cool thing about technology, isn't it?